

1. Cloudwatch로 수집하기
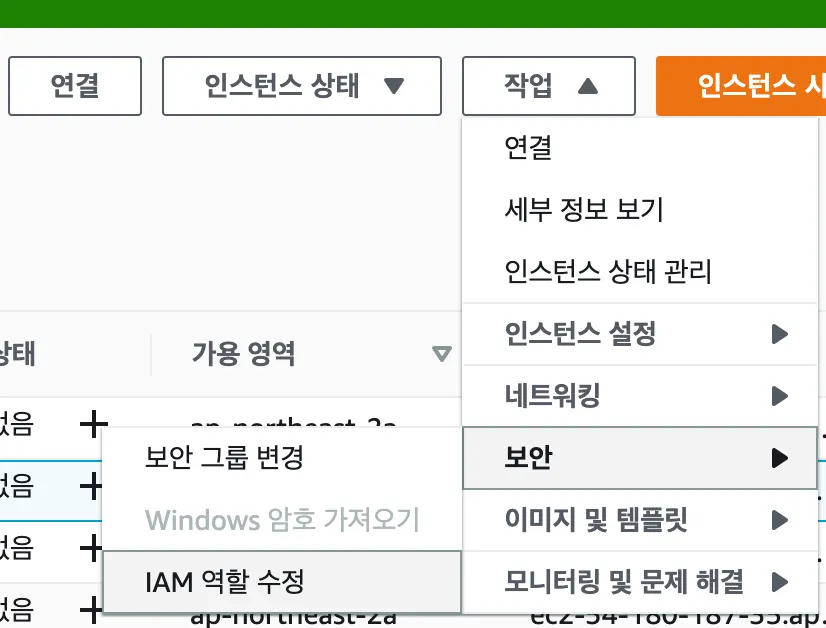
A. EC2에 IAM role 설정
•
IAM role로 CloudWatchAgentServerPolicy 권한을 가진 역할을 생성해두고 시작합니다. EC2 서버에 IAM role 권한을 부여합니다.
B. Cloudwatch agent 설정
$ wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
$ sudo dpkg -i -E ./amazon-cloudwatch-agent.deb
Bash
복사
# /opt/aws/amazon-cloudwatch-agent/bin/config.json
# 아래는 예시입니다. 필요한 지표를 추가해서 수집하세요~
{
"agent": {
"metrics_collection_interval": 60,
"run_as_user": "root"
},
"logs": {
"logs_collected": {
"files": {
"collect_list": [
{
"file_path": "/var/log/syslog",
"log_group_name": "syslog",
"log_stream_name": "{instance_id}",
"timezone": "Local"
}
]
}
}
},
"metrics": {
"metrics_collected": {
"disk": {
"measurement": [
"used_percent",
"used",
"total"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"mem": {
"measurement": [
"mem_available"
],
"metrics_collection_interval": 60
},
"netstat": {
"measurement": [
"tcp_syn_sent",
"tcp_syn_recv"
],
"metrics_collection_interval": 60
},
}
}
}
Bash
복사
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status
{
"status": "running",
"starttime": "2023-11-27T22:01:10+00:00",
"configstatus": "configured",
"version": "1.300031.0b313"
}
Bash
복사
2. 지표
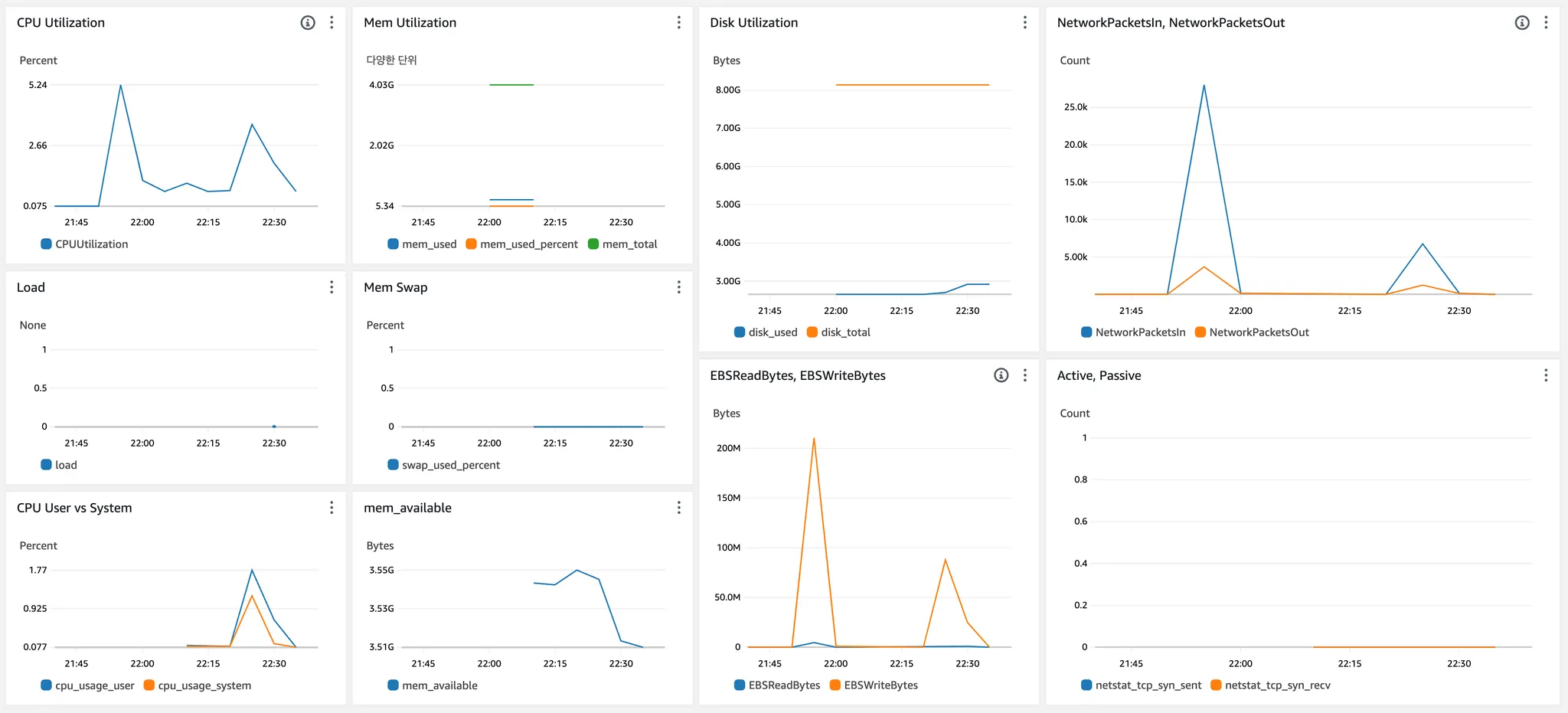
•
위젯 추가 > 유형으로 행 선택 > 원본데이터로 지표 선택 > CPU Utilization, Network In / Out, mem_used_percent, disk_used_percent 등 대시보드 추가
•
•
위의 캡쳐는 예시일 뿐이에요. 추가로 수집할만한 시스템 메트릭들도 있고, was, nginx, mysql 지표들과 로그 등도 표현 가능합니다. 물론 용도에 맞게 대시보드를 나눠서 구성해도 좋구요.
3. 애플리케이션 로그
애플리케이션의 상태를 확인하기 위해서는 로그를 남기는 것이 중요합니다. 무엇을 로그로 남겨야 할지, 로그를 어떻게 관리해야 할지 고민해보며 학습해보세요.
a. logback.xml을 작성
•
logback의 기본 설정 파일은 logback.xml 입니다. logback 라이브러리는 classpath 아래에 위치하는 logback.xml을 기본으로 찾아봅니다.
<configuration debug="false">
<!--spring boot의 기본 logback base.xml은 그대로 가져간다.-->
<include resource="org/springframework/boot/logging/logback/base.xml" />
<include resource="file-appender.xml" />
<!-- logger name이 file일때 적용할 appender를 등록한다.-->
<logger name="file" level="INFO" >
<appender-ref ref="file" />
</logger>
</configuration>
XML
복사
<property name="home" value="log/" />
<!-- appender이름이 file인 consoleAppender를 선언 -->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!--로깅이 기록될 위치-->
<file>${home}file.log</file>
<!--로깅 파일이 특정 조건을 넘어가면 다른 파일로 만들어 준다.-->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${home}file-%d{yyyyMMdd}-%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<maxFileSize>15MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<!-- 해당 로깅의 패턴을 설정 -->
<encoder>
<charset>utf8</charset>
<Pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS} %thread %-5level %logger - %m%n
</Pattern>
</encoder>
</appender>
XML
복사
•
logger: 실제 로그 기능을 수행하는 객체로 각 Logger마다 Name을 부여하여 사용합니다.
b. logback을 이용하여 logging
private static final Logger log = LoggerFactory.getLogger(Controller.class);
private static final Logger fileLogger = LoggerFactory.getLogger("file");
...
log.error("An ERROR Message");
fileLogger.info("파일 로깅 입니다.");
Java
복사
c. JSON 로그를 사용한 이벤트 로그 수집
•
src/main/resources/logback.xml
<encoder class="net.logstash.logback.encoder.LogstashEncoder" >
<includeContext>true</includeContext>
<includeCallerData>true</includeCallerData>
<timestampPattern>yyyy-MM-dd HH:mm:ss.SSS</timestampPattern>
<fieldNames>
<timestamp>timestamp</timestamp>
<thread>thread</thread>
<message>message</message>
<stackTrace>exception</stackTrace>
<mdc>context</mdc>
</fieldNames>
</encoder>
XML
복사
dependencies {
implementation("net.logstash.logback:logstash-logback-encoder:6.1")
}
Java
복사
// static import net.logstash.logback.argument.StructuredArguments.kv
log.info("{}, {}",
kv("출발지", source.getName()),
kv("도착지", target.getName())
);
);
Java
복사
4. Nginx Log
•
volume 옵션을 활용하여 호스트의 경로와 도커의 경로를 마운트합니다.
$ docker run -d -p 80:80 -v /var/log/nginx:/var/log/nginx nextstep/reverse-proxy
Shell
복사
5. Spring Actuator
dependencies {
implementation("org.springframework.boot:spring-boot-starter-actuator")
implementation("org.springframework.cloud:spring-cloud-starter-aws:2.2.1.RELEASE")
implementation("io.micrometer:micrometer-registry-cloudwatch")
}
Java
복사
cloud:
aws:
stack:
auto: false # 실행시 AWS stack autoconfiguration 수행과정에서 발생하는 에러 방지
region:
static: ap-northeast-2
management:
metrics:
export:
cloudwatch:
namespace: brainbackdoor
batch-size: 20
server:
port: 8182
endpoints:
jmx:
exposure:
exclude: "*"
web:
exposure:
include: info, health
base-path: /management
endpoint:
health:
showDetails: never
metrics:
enabled: true
YAML
복사
6. Pinpoint 구성하기
A. Collector 구성하기
git clone https://github.com/pinpoint-apm/pinpoint-docker.git
cd pinpoint-docker
git checkout 2.5.3
docker-compose pull && docker-compose up -d
Bash
복사
•
Collector로 사용할 EC2 생성 후, 위의 명령어로 collector, web, hbase 등을 구성합니다.
•
web의 포트번호 default는 8080 입니다.
•
docker-compose에서 pinpoint-agent, pinpoint-agent-attach-example, pinpoint-quickstart 등의 의존은 제거해도 됩니다.
B. Agent 구성하기
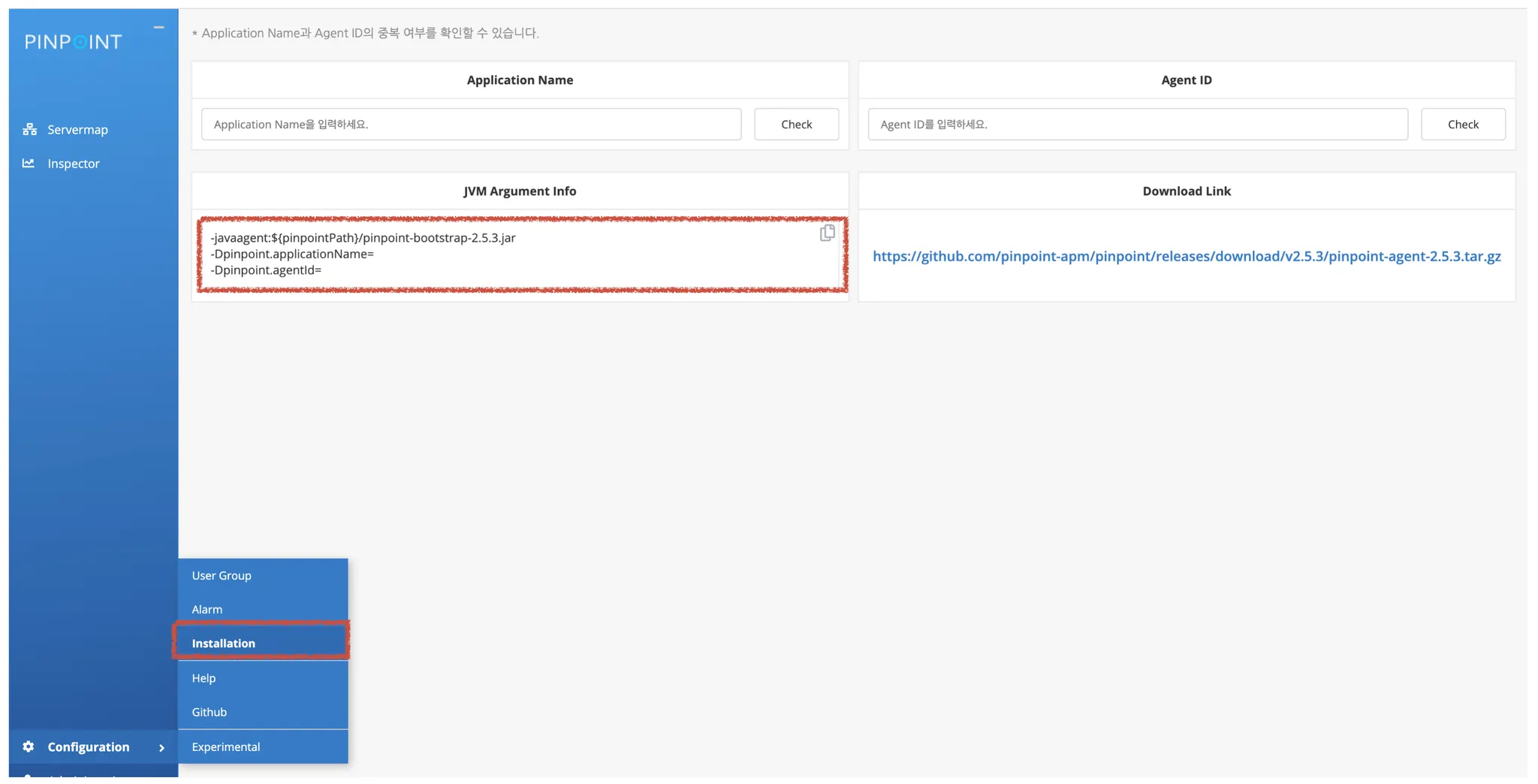
# infra-workshop/pinpoint-agent-2.5.3/pinpoint-root.config
profiler.transport.grpc.collector.ip=[Collector IP]
...
# 부하테스트 등 환경을 고려해서 샘플링을 고려
# eg. 1: 100% 20: 5% 50: 2% 100: 1%
profiler.sampling.counting.sampling-rate=1
Bash
복사
# front 모듈을 가정할 때, 아래와 같이 옵션을 추가하면 됩니다.
# 프로젝트의 최상위 경로에서 자바 명령어로 프로세스를 실행하거나,
# IntelliJ의 Configurations 화면에서 VM Options에 추가해서 진행해보세요.
-javaagent:pinpoint-agent-2.5.3/pinpoint-bootstrap-2.5.3.jar
-Dpinpoint.agentId=front-api
-Dpinpoint.applicationName=front-api
Bash
복사
C. Pinpoint 웹 콘솔 살펴보기
a. Servermap
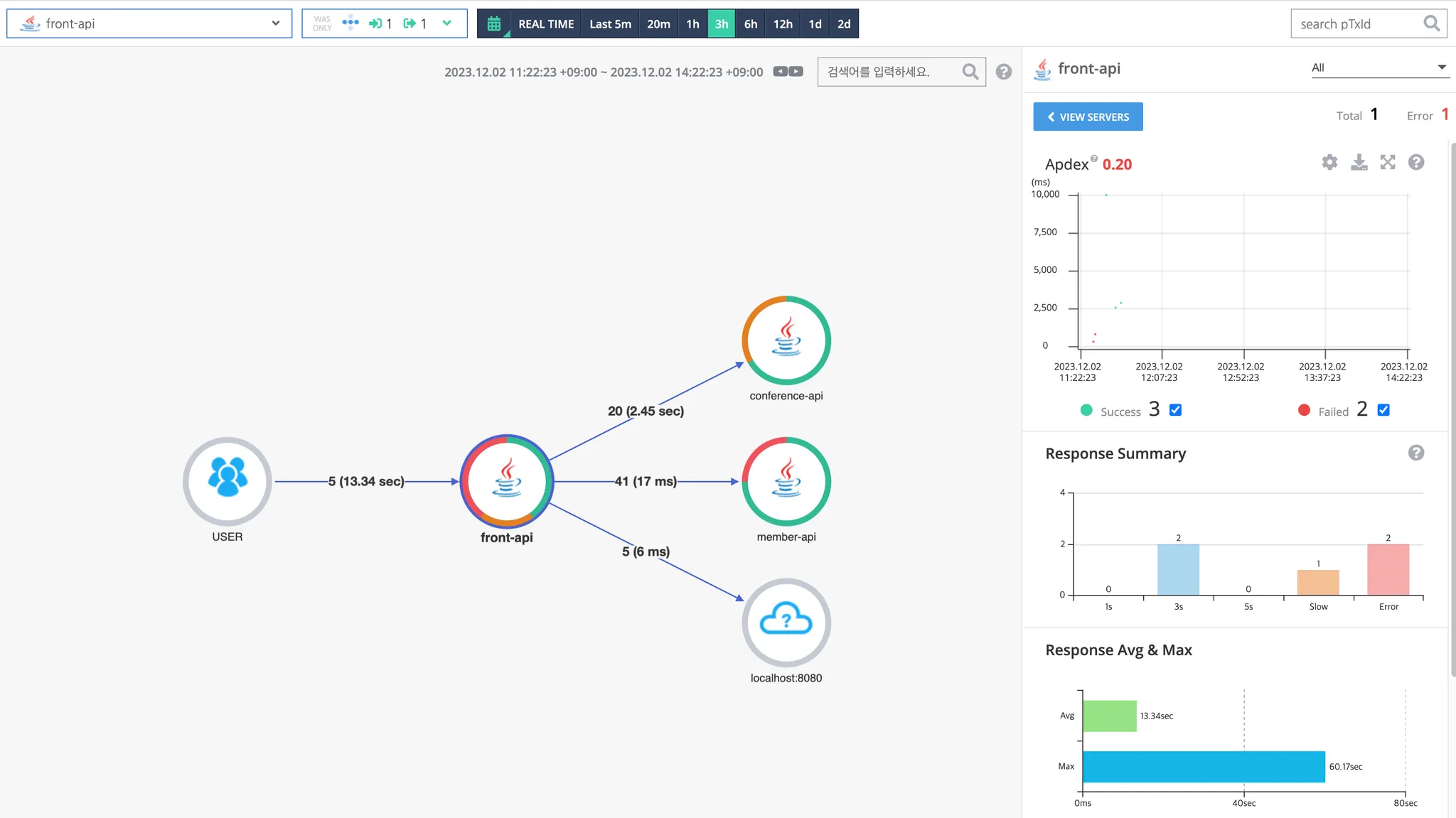
서버간 관계 및 트래픽 평균 응답시간, 응답 분포 등을 확인할 수 있습니다. 우측 상단의 응답시간 분포 영역을 마우스 드래그를 통해 특정 콜에 대한 추적이 가능합니다.
b. Callstack Trace
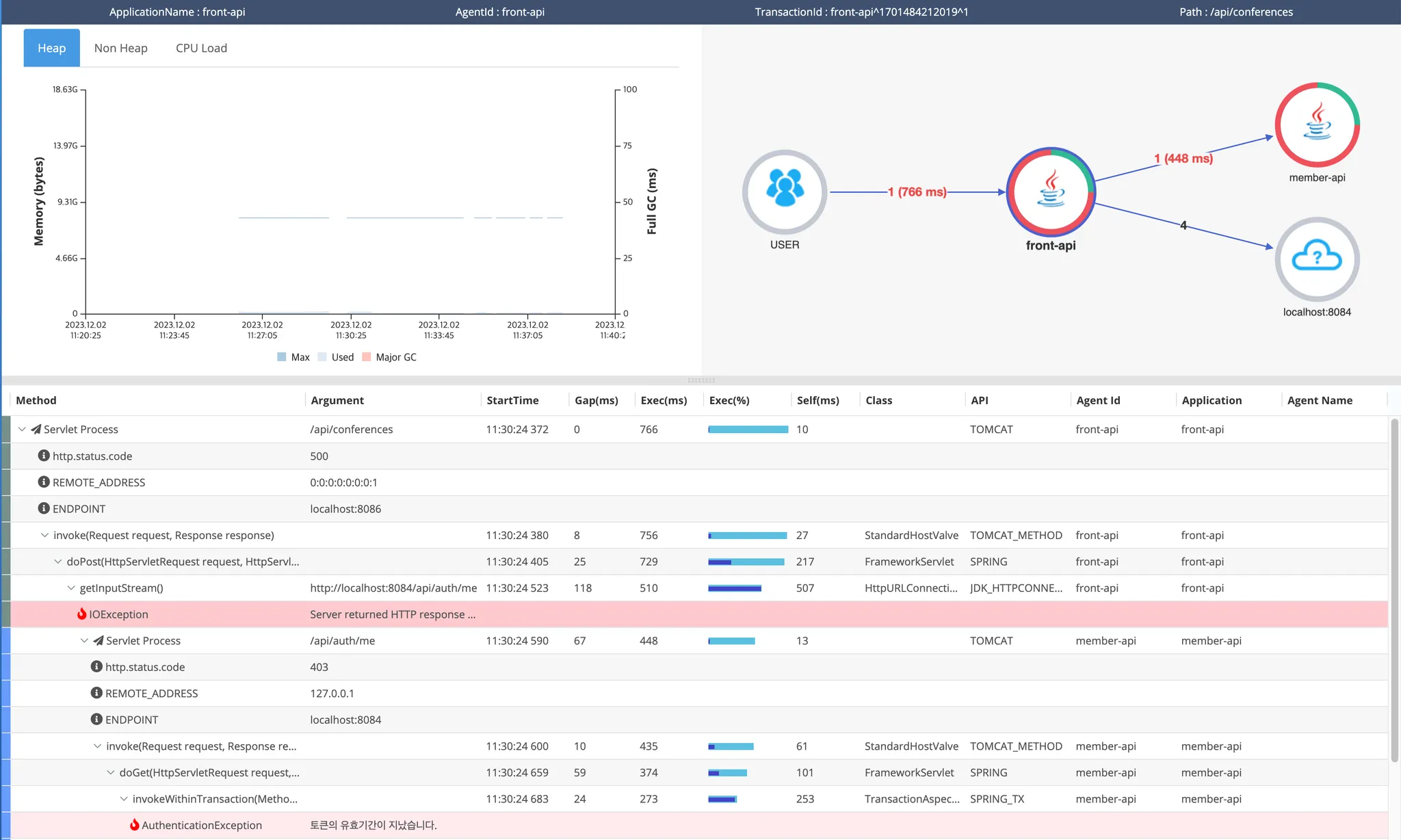
mixed view
요청에 대한 소스레벨의 Trace View를 제공합니다. SQL 쿼리, 에러 로그 및 병목지점 등을 확인할 수 있고, 이를 Call Tree, Server Map 및 Mixed View 등으로 확인해 볼 수 있습니다.
c. Inspector
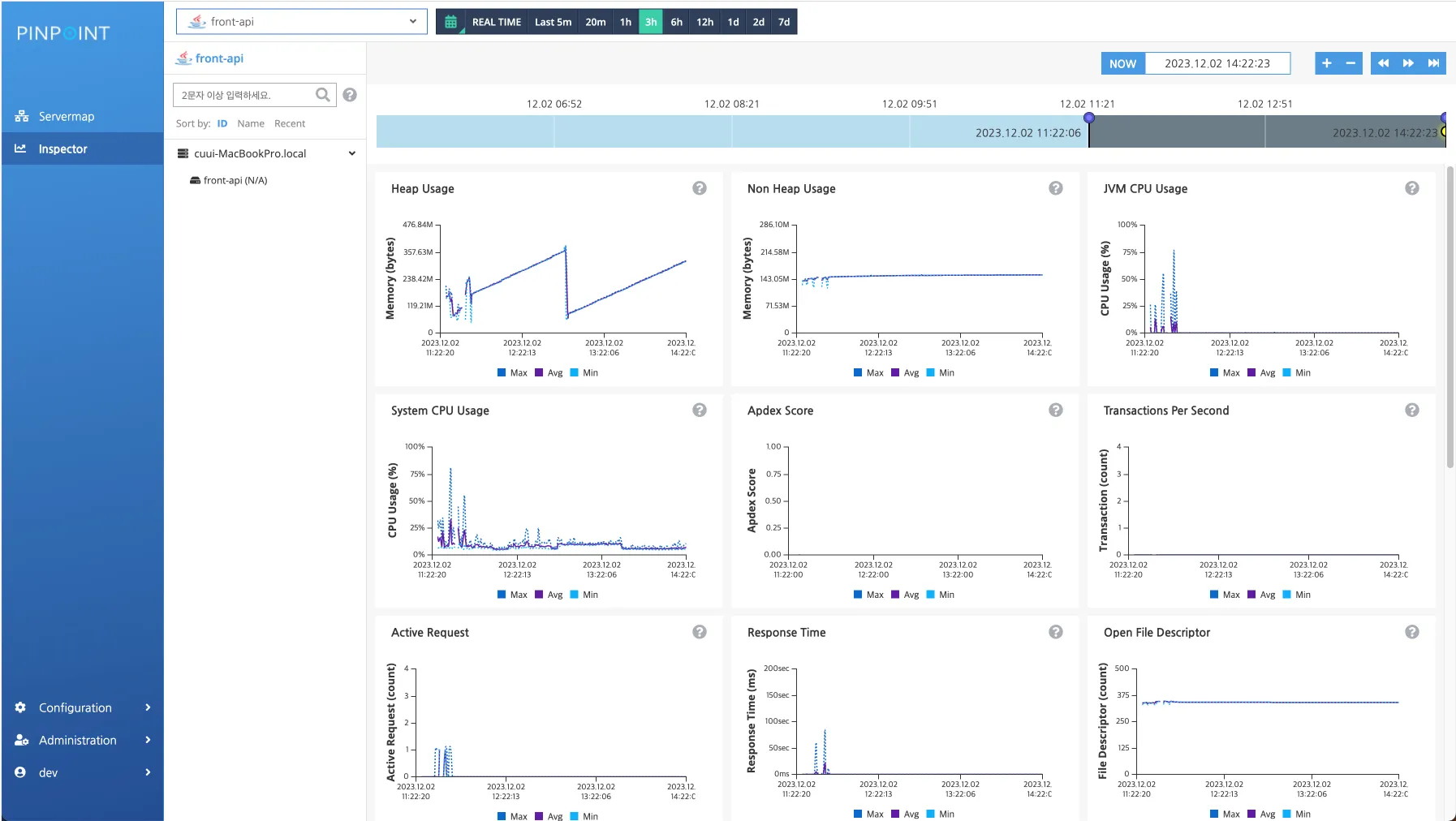
CPU, memory, tps, datasource connection count 등 agent 들의 리소스 지표를 확인할 수 있습니다.