

1. 특징
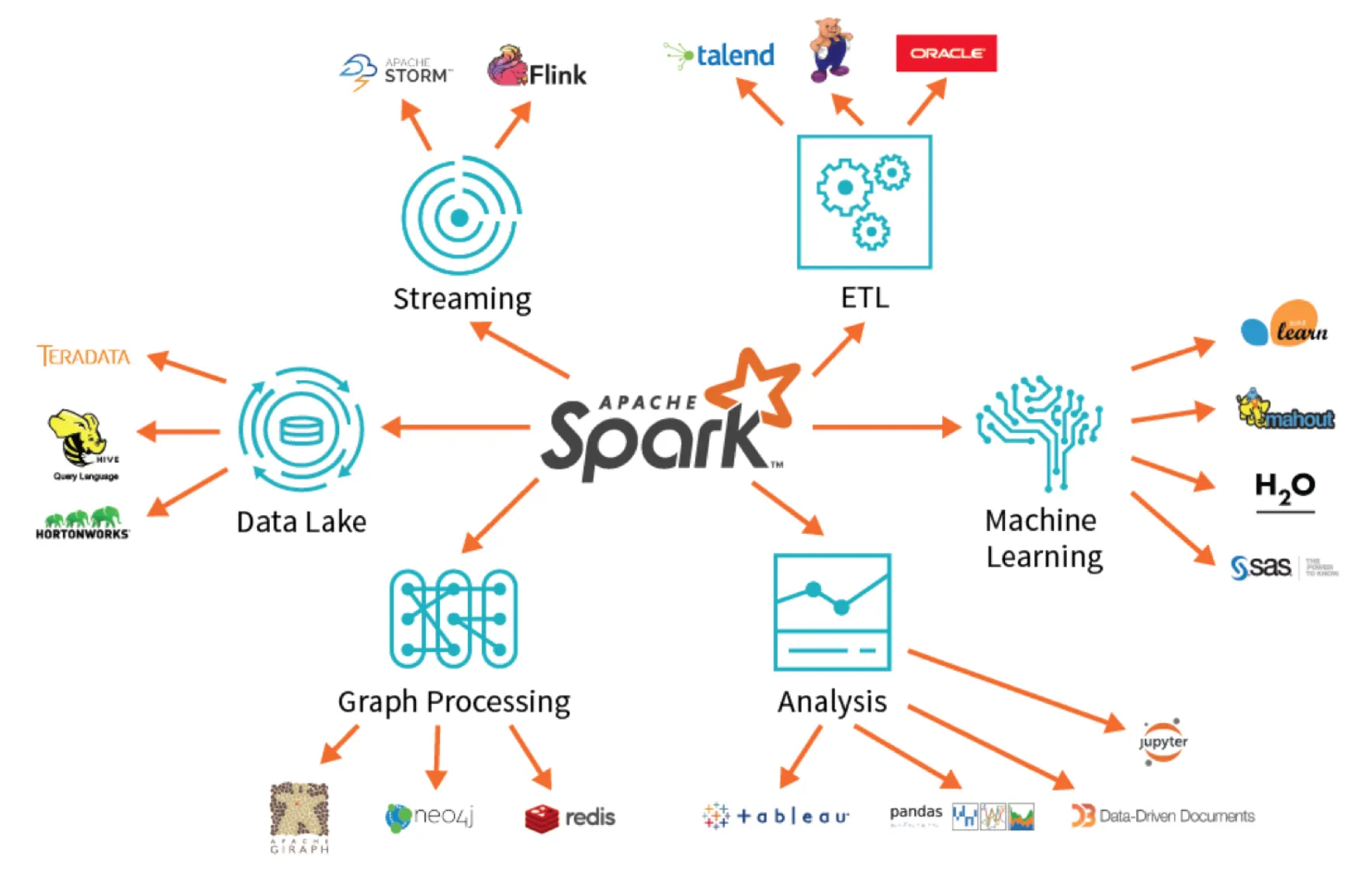
1) Apache Spark는 데이터 처리를 위한 범용 프레임워크이다. 데이터 파이프라인을 위해 많이 사용되며, 산업 표준에 가깝다. Spark는 MapReduce와 유사한 일괄처리 기능, 실시간 데이터 처리기능, SQL과 유사한 정형 데이터 처리 기능, 그래프 알고리즘, 머신러닝 알고리즘을 모두 단일 프레임워크로 통합했다.
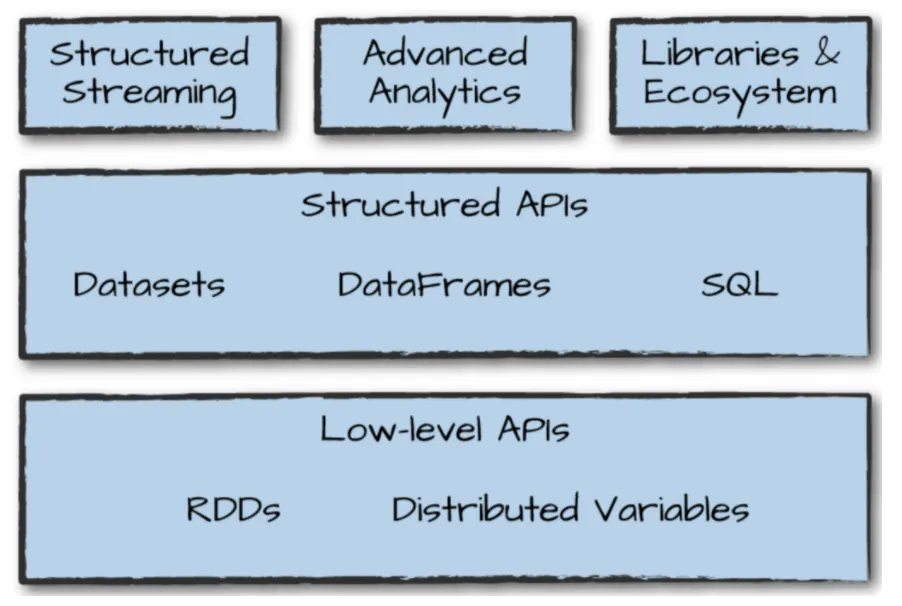
2) 다양한 Layer의 API, 다양한 형태의 API (Dataset, Dataframe, Spark SQL)를 지원해준다.
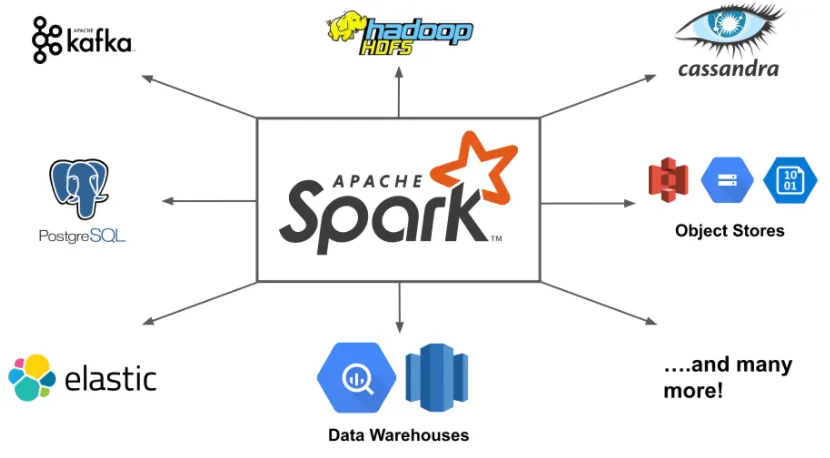
3) 다양한 Storage와 연동되는 Connector가 존재하여 데이터 추출 및 저장이 가능하다.
4) Yarn, Mesos, k8s 등 환경을 위한 Cluster Manager가 있으며, SQL, Python, Scala 등을 위한 터미널, Jupyter 등 다양한 실행 모드 및 환경을 지원한다.

2. Why not RDBMS?
IT 환경이 고도화되어 처리할 데이터가 수백억건으로 증가함에 따라, 기존의 단일 소프트웨어로는 의미있는 정보를 검색/시각화/예측/분석 등을 하기에 어려움이 있다. DB 쿼리 성능의 주요 제약사항 중 하나는 쿼리의 순차적인 실행이다. 대부분의 DB는 다수의 프로세서를 사용할 수 있지만, 하나의 쿼리를 위해 다수의 프로세서를 사용하지는 않는다. 다수의 쿼리를 한번에 수행하기 위해 (batch 등)병렬성을 활용하기는 한다. 하나의 쿼리를 병렬로 실행한다고 해도 DB 성능은 디스크 I/O속도에 의해 여전히 제한될 수 있다. 그리고 기존의 RDBMS를 Distributed Architecutre로 구성할 경우, ACID를 위해 복잡한 locking 방식과 복제 방식을 사용할 수 밖에 없다.

이에 OLAP(Online Analytical Processing), 텍스트 처리, 스트림 처리, 고차원 데이터 처리 등에 있어 특화된 아키텍처로 여러 방법론이 소개되었다. 다만, 데이터를 여러 노드에 나눠 처리한 후 결합하는 경우에도(Distributed Data Parallelism), 네트워크상의 오버헤드가 발생할 수 있다. 따라서 단일 머신에서도 처리할 수 있는 데이터셋을 다룰 때는 비효율적일 수 있으며, 대량의 원자성 트랜잭션을 빠르게 처리해야 하는 OLTP 작업에는 적합하지 않다.

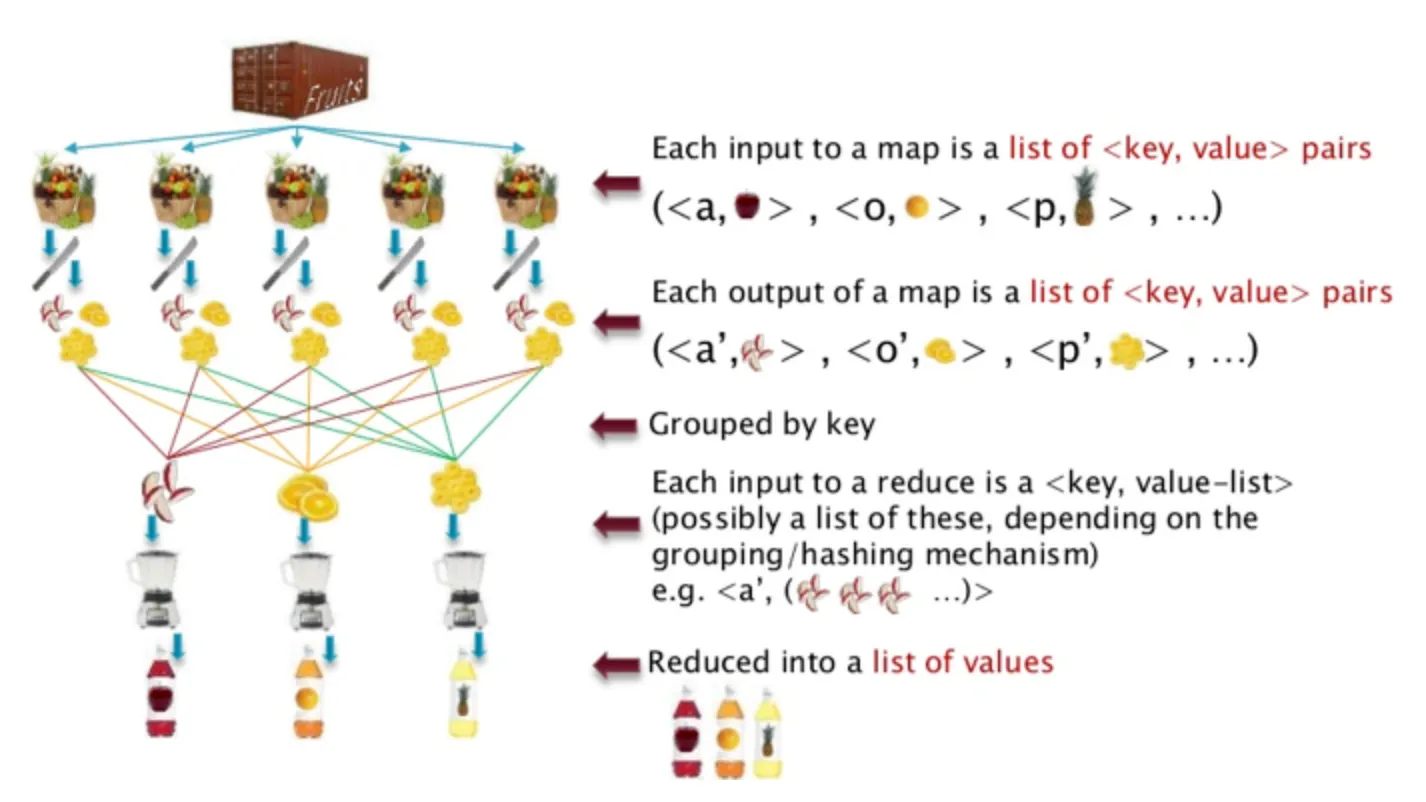
3. Why not MapReduce?
과거 구글은 MapReduce를 통해 빅데이터 관련 이슈를 해결하였다. MapReduce란, 문제를 쉽게 병렬화할 수 있게 나눈 후, 장비 클러스터 전체에서 이들을 조정하는 계산 패러다임이다. Hadoop은 분석을 병렬로 수행할 수 있도록 나눠주며, HDFS는 많은 디스크에 흩어져 있는 데이터를 병렬로 읽는다.
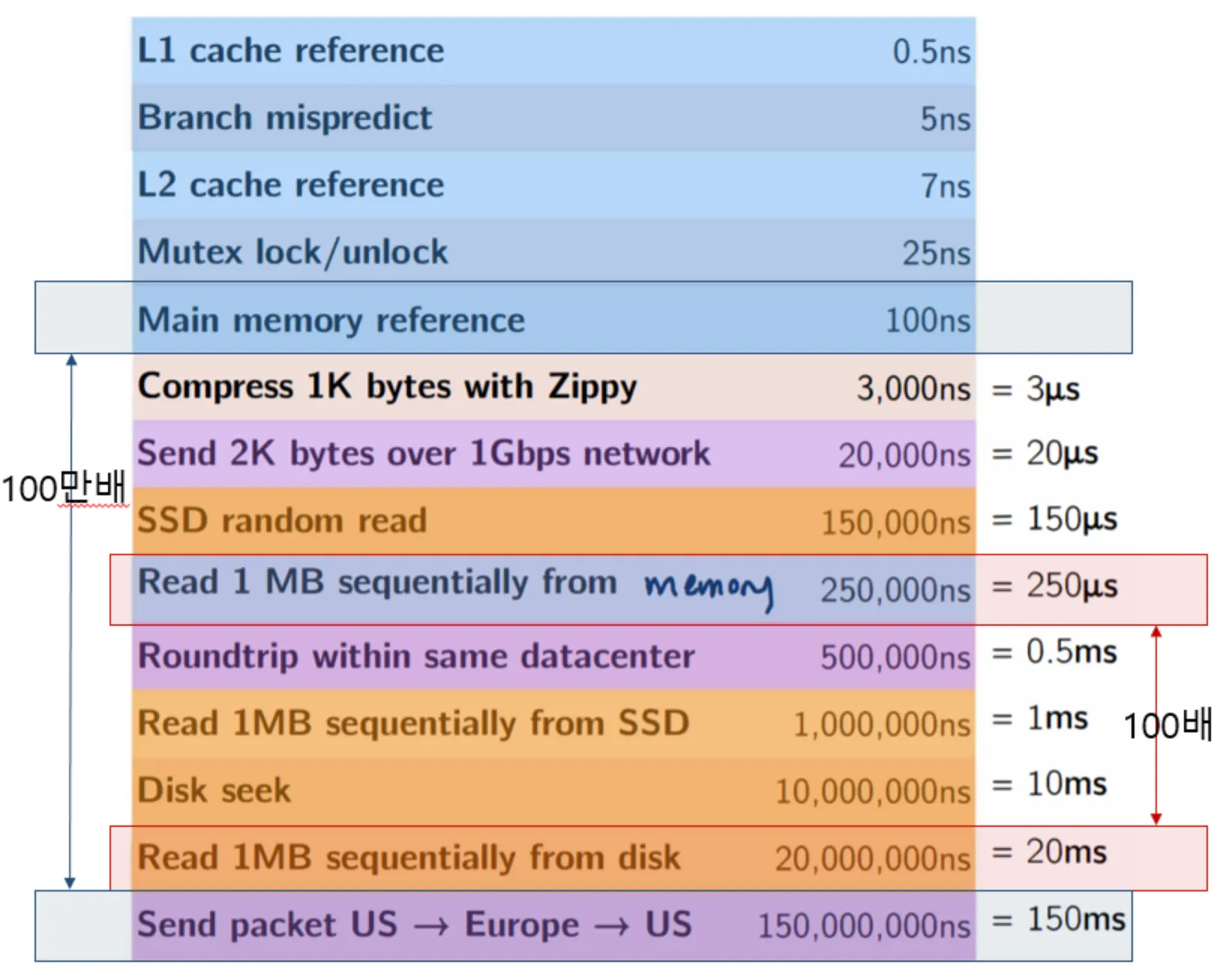
하지만 MapReduce 잡의 결과를 다른 잡에서 사용하려면 HDFS에 저장해야 하여 반복 알고리즘에는 본질적으로 맞지 않다. 그리고 무엇보다도 느리다. 메모리는 디스크에 비해 100배 빠르며 네트워크 통신에 비해 일반적으로 100만배 빠르다. Hadoop은 Iteration할때마다 filesystem에 써야 한다.

4. What's Spark's advantages?
Hadoop이 HDFS + MapReduce 처리 엔진으로 구성된데 반해, Spark는 대량의 데이터를 메모리에 유지하는 독창적인 설계로 계산 성능을 대폭 끌어올렸다. 따라서 Spark는 Hadoop MapReduce보다 10~100배 빠른 속도로 같은 작업을 수행한다.
Spark는 여러 데이터 소스에서 읽을 경우 persist(), cache()를 사용하며, Functional Programming 개념을 가져와서 Latency 문제를 해결하였다. 그리고 데이터를 In-memory에 유지하며 Immutable하기에, Functional transformation을 replaying해줌으로써 Fault tolerance를 확보할 수 있다.
또한 Lazy execution을 통해 네트워크 병목현상을 피할 수 있다. Eager execution은 바로 실행되는데 반해, Lazy execution은 Action을 호출하기 전까지는 Transformation의 계산을 실제로 실행하지 않는다. RDD에 Action이 호출되면 Spark는 해당 RDD 계보를 살펴보고, 이를 바탕으로 연산 그래프를 작성하여 Action을 계산한다. 따라서 빈번한 반복 연산이 이루어질 경우 마지막에 메모리에 올려 계산하여 값을 작성함으로써 IO를 줄일 수 있으며, 조건 검색 혹은 count() 등의 경우에서 Full-scan 비용을 줄일 수 있다.
val largeList: List[String] = ...
val wordsRdd = sc.paralleize(largeList)
val lengthsRdd = wordsRdd.map(_.length) -> lazy하기 때문에 아직 아무 작업도 안함
val totalChars = lengthsRdd.reduce() -> 이때 실행이 됨.
Kotlin
복사
